NWO VIDI
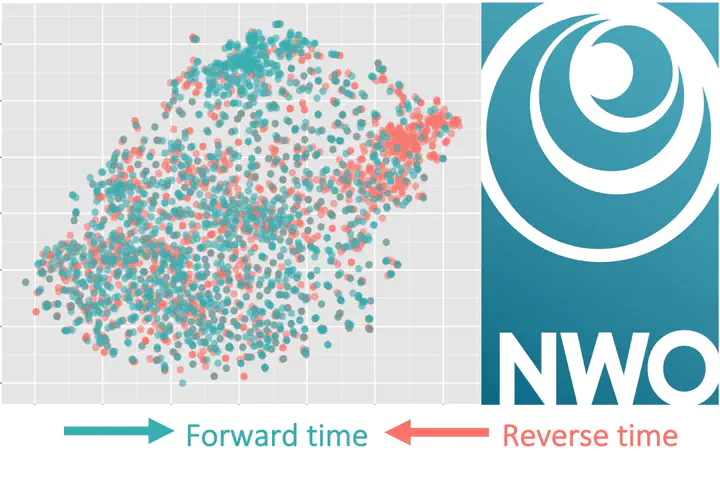 Machine learning algorithms cannot distinguish forward from reverse arrow of time in videos
Machine learning algorithms cannot distinguish forward from reverse arrow of time in videos
From Facebook’s 3.5 billion live streams to the complex MRI sequences and satellite footage monitoring glaciers, video recognition becomes increasingly relevant. Ultimately it will enable to understand what is happening, where and when in videos by artificial intelligence. Encouraged by the breakthrough of deep representation learning in static image recognition, today’s video recognition algorithms emphasize static representations. In effect, they are time invariant. Ignoring time like this suffices in simple short videos, but in tomorrow’s applications recognizing time is imperative: it determines whether a suspect draws something in or out of their pocket, where a tumour will move in the MRI or at which rate glaciers melt in satellite footage. For all these cases and more, video algorithms must be time equivariant, that is yield representations that change proportionally to the temporal change in the input. As we move to video understanding where temporality is critical, time equivariant algorithms are a must.
This is a 5-year research program that studies, develops and evaluates time equivariant video algorithms. To achieve this, we will approach video algorithms from two angles: time geometry, and time supervision. Geometry helps with accounting for innumerable patterns without blowing up the representation complexity. Time supervision helps with learning time equivariance, without relying on strong manual supervision. A temporal decathlon competition will be introduced to the community to evaluate, disseminate and utilize the temporal behaviour of video algorithms. The decathlon will serve as a proxy for designing better video algorithms more efficiently. It will also open up video algorithms to other disciplines, where researchers have videos and know their temporal properties but do not have a common reference point. All research will be published in the top relevant conferences and journals. The major innovation of the proposed research is understanding and exploiting time in video algorithms.
Efstratios Gavves
Causal Computer Vision & Learning Dynamics
Causal Computer Vision, Leanring Dynamics